

Richard Florida on Grocery Prices
Richard Florida argues here that - counterintuitively - groceries actually cost less in big cities. If I understand him correctly this is because in bigger cities there is a bigger choice of products, including cheaper ones. Standard price indeces are based on product baskets that compare for example 1L of low fat milk of brand A in various places. In real live consumers might substitute brand A with a cheaper brand B and in big city this is more likely because of the greater variety of products.
He uses the graph below from this study titled Goods Prices and Availability in Cities (which I have NOT read) to make the following point:
The chart below, from the study, shows the relationship: The larger the city’s population, the more products. (“UPC” stands for Universal Product Code, or the unique barcode carried by each product and scanned during purchase.) (Handbury and Weinstein) […] Overall, the study finds that a doubling in a city size leads to a 20 percent increase in the number of available products.
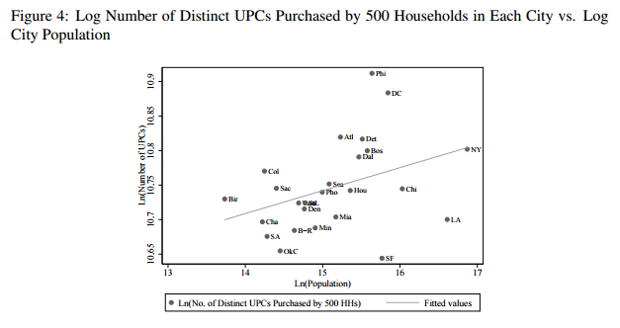
I have two technical issues with this grah and on top of that I fail to see how this particular figure supports the argument:
- For a regression of double-log data points that shows as much scatter as in this graph, the authors need to give an error estimate for the regression line.
- Yes it is a double-log plot, but with a computer it is almost no extra work to use the underlying non-log number to label the axes. For the sake of your readers please put in that extra work. The axis ranges can of course be computed from the graph (e.g. Ln(Population) = X => exp(X) = Population). Cities populations range from exp(13.8) = 980,000 to exp(17) = 24,155,000. This is a hint that something more is amiss here: The latter number is for NY, wich according to the text has a population of 8.2 Million. So the axis title Ln(Population) is either wrong or NY includes a bigger metropolitan area than the text states. Maybe the text of the original paper would explain that. The Number of UPC ranges from exp(10.65) = 42,192 to exp(10.9) = 54,176 (which in light of incorrect population labelling has to be treated with suspiscion).
These to pieces of information are actually necessary to assess the significance of the finding. Looking at the figure as is I habe doubts. If the six cities with Ln(Population) closest to 16 are taken out of the regression the correlation falls apart (of course one is not allowed do this kind of subjective data exclusion - but if something like that completely changes a correlation that correlation wasn’t particularly robust in the first place…). Also, just looking at the data I get a feeling that a correlation just as significant might be found if cities were plottet according to latitude rather than Ln(Population) - and then we might be on to something.
Of course the original paper might address these issues - but it is behind a paywall.
But much more interesting is the fact that what the graph shows are the “No. of Distinct UPCs purchased by 500 HHs” (households, I assume). So the figures does not say anything about what choice consumers have but something about what choices consumers make: In bigger cities they tend to go for a greater variety of products. They could do that, if the choices available were exactly the same. More importantly, they could go for a smaller variety of products and still substitute more expensive brands for cheaper ones. So the graph is not supporting the argument at all. Is the argument correct? I guess so. Is it relevant? Probably not, a Florida points out in his last paragraph.
Why do I acutally bother to put this in writing? I guess the public sloppy use of sophisticated statistics just bugs me. Onces I get around to implementing a tag cloud on this blog, you’ll be able to see other examples of this obsessive behaviour by looking for the tag public statistics